AI 换脸的技术原理与行业应用
AI 换脸是通过深度学习算法提取目标人物面部特征,并将其覆盖至另一段视频或图片中的视觉重构技术。到 2026 年 3 月,该技术已从简单的娱乐滤镜演变为工业级工作流,广泛应用于电商模特替换、远程协作及司法鉴定等领域。
其核心逻辑依赖于自动编码器(Autoencoder)的对称结构。
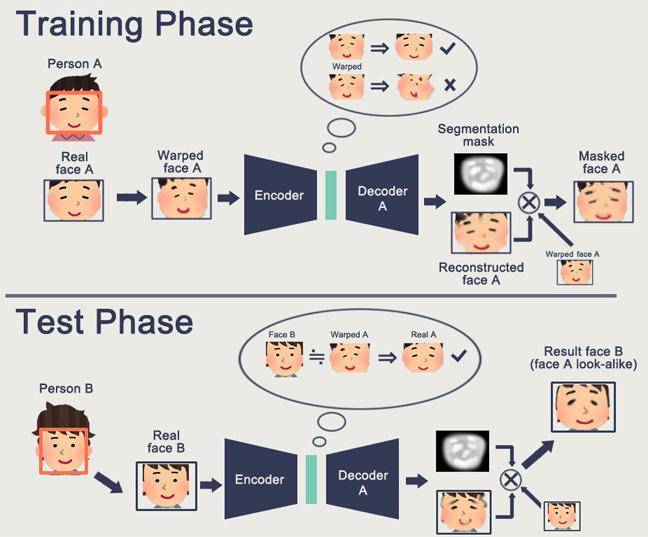
算法使用两个相同的解码器,但通过不同的编码器分别学习 A 脸和 B 脸的特征。当编码器将 A 脸压缩为数学向量后,强制使用 B 脸的解码器还原,从而使 A 脸的表情与光影套用在 B 脸的轮廓上。目前的实时换脸则依赖 GANs 或 Diffusion-based 渲染,将延迟压低至 30 毫秒以内,使得视频会议中的数字人格几乎无感知地替换真实身份。
电商行业已将 AI 换脸作为标准降本方案。 在 Shein 或 Temu 等平台,部分模特面孔由算法合成。品牌方无需为不同国家市场聘请模特,只需拍摄一套样衣图,即可快速切换目标市场的主流面孔。这虽极大压缩了拍摄成本,但也引发了认知困境:当消费冲动建立在经过算法精准计算的虚拟美貌之上,这种消费行为在某种程度上是对真实审美的误导。
职业面试中的 AI 换脸则推高了信任成本。 2025 年 2 月,业内出现开发者在技术面试中利用实时换脸掩盖身份,并配合 ChatGPT 生成答案的案例。由于面试官看到的形象与实际操作者不符,企业正被迫将远程视频面试转向包含现场核验或多维度身份验证的混合模式。
高质量 AI 换脸的实操部署指南
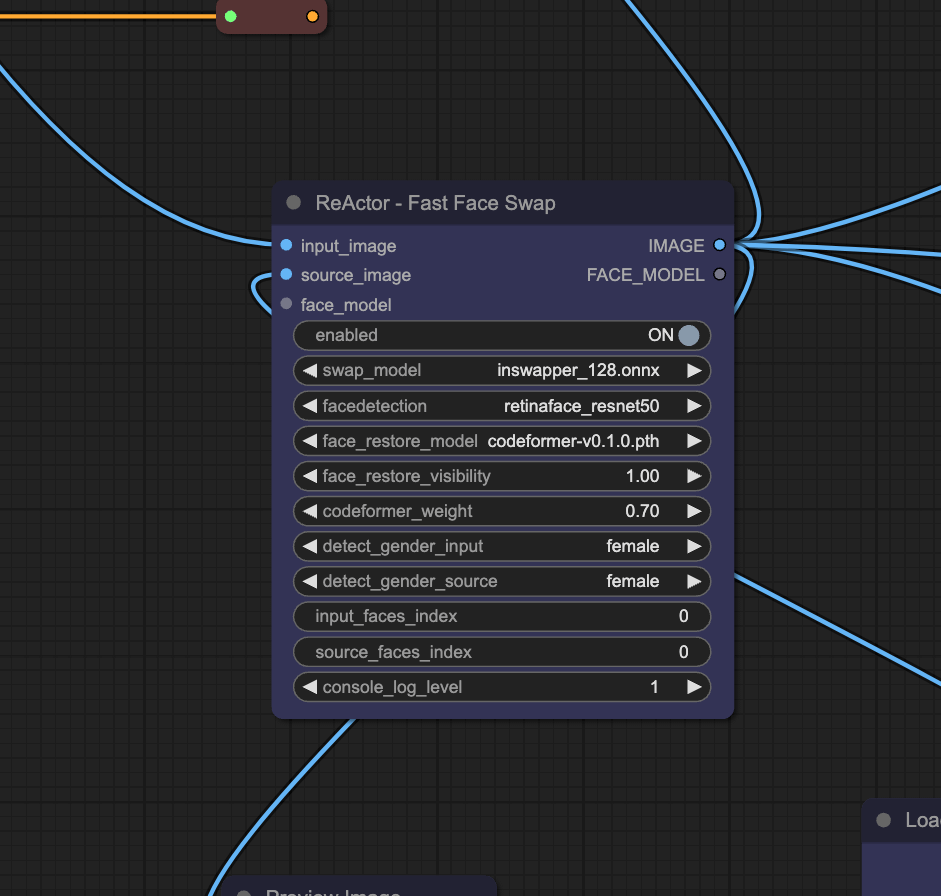
若要实操高质量的 AI 换脸,目前可验证的路径是使用 Stable Diffusion 的 ReActor 插件或 DeepFaceLab。具体部署步骤如下:
需配置 NVIDIA RTX 3060 或以上显卡(建议显存 12GB),安装 Python 3.10 及 Stable Diffusion WebUI。在扩展插件面板安装 ReActor 后,必须将预训练模型 inswapper_128.onnx 手动放入 models/insightface 文件夹,否则启动时会因找不到模型而报错。

源图(Source Image)需清晰、正面且无遮挡,分辨率建议在 512x512 像素。目标图(Target Image)的光影必须与源图尽可能一致。若源图为顶光而目标图为侧光,合成面孔会产生明显的“塑料感”,此时需手动调整亮度与对比度使其趋同。
在 ReActor 面板中,将 Face Restoration(面部修复)选择为 CodeFormer 或 GFPGAN,Visibility 建议设在 0.5 到 0.8 之间,以平衡清晰度与自然度。Gender Detection 设为 Both 以准确捕捉面部锚点。生成后若出现边缘接缝,可用局部重绘(Inpaint)功能,在 0.4 左右的重绘强度下进行抹平。
视频换脸需将视频拆分为单帧序列,逐帧处理后再用 FFmpeg 合成。针对常见的闪烁(Flickering)问题,需引入时间轴平滑算法,计算前后帧像素偏移量并进行加权平均,确保 30fps 下无明显跳变且表情同步。
局限性、伦理挑战与工具选择
技术的普及也带来了伦理挑战。2026 年 5 月,法律界关于 AI 性别换脸刑事化的讨论集中在“几乎裸露(Near-Nude)”的定义上。目前立法趋势正从版权保护转向人格权保护,即未经许可将他人面孔合成至敏感图像,无论程度如何,均应视为侵权。
AI 换脸并非万能,其局限性依然明显: 首先是极端角度失效(头部侧转超过 60 度时易扭曲);其次是遮挡物处理缺陷(易产生穿模现象);最后是情绪缺失(无法模拟细微肌肉抽动)。
不同工具的选择逻辑
| 工具名称 | 核心优势 | 劣势/成本 | 适用场景 |
|---|---|---|---|
| DeepFaceLab | 效果顶级,支持深度训练 | 学习曲线陡峭,耗时长 | 电影工业级制作 |
| ReActor / InsightFace | 即时生成,无需训练 | 细节丢失较多 | 社交媒体快照 |
| DeepFaceLive | 支持直播流,低延迟 | 硬件要求极高 | 虚拟主播/直播 |
如何验证视频中的人脸是否为 AI 换脸?
建议在重要身份核验场景中,引入 3D 深度摄像头(如结构光技术或要求对方执行随机动作(如快速左右转头并眨眼),因为实时换脸在处理大幅度快速运动时仍会出现掉帧或撕裂。在 2026 年,视频已不再是真相的绝对证据。
ReActor 插件安装后无法运行怎么办?
绝大多数情况是由于缺少 inswapper_128.onnx 模型文件或 InsightFace 依赖库安装失败。请检查模型是否放置在正确的 models/insightface 目录下,并确保 Python 环境已通过 pip 安装最新版本的 insightface。
如何解决换脸后的边缘接缝问题?
可以通过在 Stable Diffusion 中使用局部重绘(Inpaint)功能,将遮罩涂在接缝处,在 0.4 左右的重绘强度下进行微调,使肤色与光影自然过渡。